Generalization Predictions
The below sliders illustrate the pattern of generalization predicted as a function of the amount of data observed (N). Male denoted with hats. While it may appear that the model has learned the correct extension for the word with very few data points, this is not necessarily the case. For this visualization, the predictions are fixed to this family tree context. The model might actually make incorrect generalizations on other trees. Refer to Figure 2 in the main paper for how many data points are required for the model to learn the context independent "correct" meaning.
Pukapuka
Kainga

Based on the model, we would expect learners to initially over-generalize to all members of the learner's generation before restricting to just the men of the learner's generation.
Taina
Based on the model, we would expect learners to initially over-generalize to all members of the learner's generation and all women, then restricting to just the learner's generation before settling on just the women of the learner's generation.
Matua-tane
Based on the model, we would expect learners to initially over-generalize to all members of the learner's parent's generation, then restricting to just the men, then restricting to those related to the learner by blood.
Matua-wawine
Based on the model, we would expect learners to initially over-generalize to all members of the learner's parent's generation, then restricting to just the women, then restricting to those related to the learner by blood.
Tupuna-tane
Based on the model, we would expect learners to initially over-generalize to all men before restricting to members of the learner's grandparent's generation.
Tupuna-wawine
Based on the model, we would expect learners to initially over-generalize to all women before restricting to members of the learner's grandparent's generation.
English
Mother
Based on the model, we would expect learners to initially over-generalize to both parents before restricting to women.
Father
Based on the model, we would expect learners to initially over-generalize to both parents before restricting to men.
Brother
Based on the model, we would expect learners to initially over-generalize to their parent's children before restricting to men.
Sister
Based on the model, we would expect learners to initially over-generalize to their parent's children before restricting to women.
Grandma
Based on the model, we would expect learners to initially over-generalize to all blood related members of their grandparent's generation before restricting women.
Grandpa
Based on the model, we would expect learners to initially over-generalize to all blood related members of their grandparent's generation before restricting men.
Aunt
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to women, before exlcuding their parent.
Uncle
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to men, before exlcuding their parent.
Cousin
Based on the model, we would expect learners to initially over-generalize to all members of their generation before exlcuding their parent's children.
Turkish
Anne
Based on the model, we would expect learners to initially over-generalize to their parents before restricting to women.
Baba
Based on the model, we would expect learners to initially over-generalize to their parents before restricting to men.
Abi
Based on the model, we would expect learners to initially over-generalize to their parent's children before restricting to men.
Abla
Based on the model, we would expect learners to initially over-generalize to their parent's children before restricting to women.
Anneanne
Based on the model, we would expect learners to initially over-generalize to all blood related members of their grandparent's generation then restricting women, then to maternal relations.
Babaanne
Based on the model, we would expect learners to initially over-generalize to all blood related members of their grandparent's generation then restricting women, then to paternal relations.
Dede
Based on the model, we would expect learners to initially over-generalize to all blood related members of their grandparent's generation before restricting men.
Hala
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to women, before settling on their father's sisters.
Dayi
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to men, before settling on their mother's brothers.
Teyze
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to women, followed by maternal blood relations, before exlcuding their mother.
Amca
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to paternal blood relations, followed by men, before exlcuding their father.
Eniste
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to men, before exlcuding parent's siblings and then parents.
Yenge
Based on the model, we would expect learners to initially over-generalize to all members of their parent's generation then restricting to women, before exlcuding blood relations and parents.
Kuzen
Based on the model, we would expect learners to initially over-generalize to all members of their generation before exlcuding their parent's children.
Yanomamö
Haya
Based on the model, we would expect learners to initially over-generalize to all blood related members of their parent's generation then restricting by coresidence, before restricting to men.
Naya
Based on the model, we would expect learners to initially over-generalize to all blood related members of their parent's generation then restricting by coresidence, before restricting to women.
Eiwa
Based on the model, we would expect learners to initially over-generalize to all members of their generation then restricting to men, before restricting to siblings and parallel cousins.
Amiwa
Based on the model, we would expect learners to initially over-generalize to all members of their generation then restricting to women, before restricting to siblings and parallel cousins.
Soaya
Based on the model, we would expect learners to initially over-generalize to all blood related members of their parent's generation then restricting to men, before narrowing to maternal brothers.
Yesiya
Based on the model, we would expect learners to initially over-generalize to all blood related members of their parent's generation then restricting to women, before narrowing to paternal sisters.
Soriwa
Based on the model, we would expect learners to initially over-generalize to all members of their generation then restricting to men, before restricting to cross-cousins.
Suaboya
Based on the model, we would expect learners to initially over-generalize to all members of their generation then restricting to women, before restricting to cross-cousins.
Pareto-Front
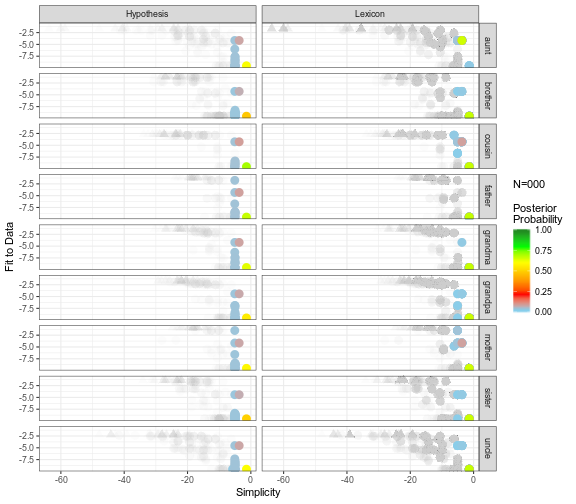
Each hypothesis is plotted according to its fit to the data, or average log likelihood per data point (y-axis), and simplicty, or log prior (x-axis). The hypotheses constituing the top 95% posterior probability at a given data amount are colored according to probability. Hypotheses that denote the correct set of referents in every context are plotted as triangles. The left column tracks the movement of probability over the space if we were to treat each hypothesis as independent. The right column tracks the movement of probability over the space if we were to treat hypotheses as a lexicon (see Appendix C). To start the animation, click on the tree. To reset the animation, click again.